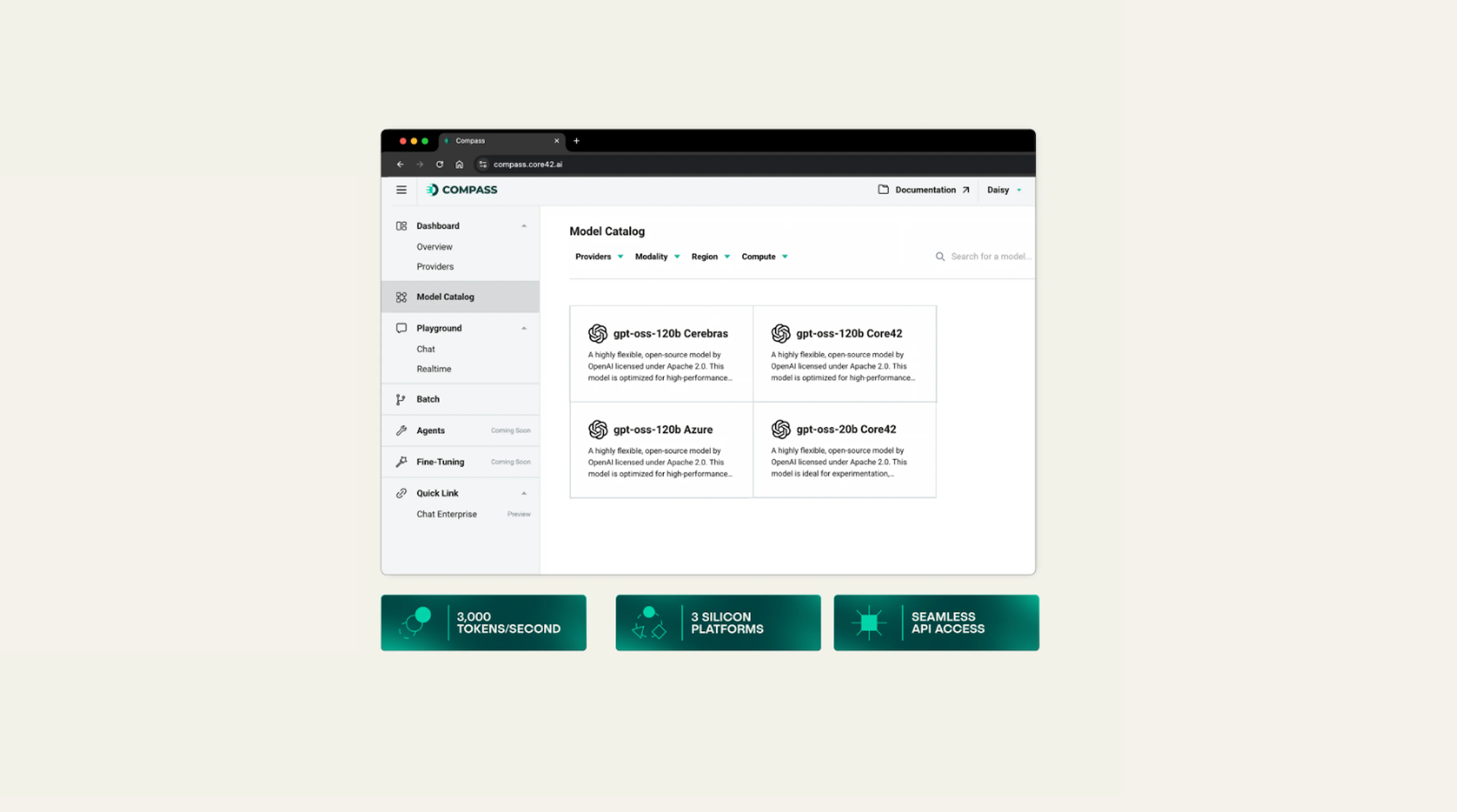
Cerebras, the fastest AI provider in the world, and Core42, a G42 company specializing in sovereign cloud and AI infrastructure, announced the global availability of OpenAI’s gpt-oss-120B. Core42 AI Cloud via Compass API brings Cerebras Inference at 3,000 tokens per second to power enterprise-scale agentic AI.
Cerebras has been a pioneer in supporting open-source models from OpenAI and Meta, consistently achieving the fastest inference speeds as verified by independent benchmarking firm Artificial Analysis. Together, Cerebras and Core42 bring these capabilities to enterprises and developers worldwide through a single platform.
“Together with Cerebras and Core42, we’re making our best and most usable open model available at unprecedented speed and scale,” said Trevor Cai, Head of Infrastructure, OpenAI. “This collaboration will give enterprises, researchers, and governments around the world the ability to build real-time reasoning applications with extraordinary efficiency.”
Powered by the Cerebras CS-3 and wafer-scale engine (WSE), the collaboration sets a new benchmark for real-time reasoning with ultra-low latency and radically lower cost-per-token than GPUs, instantly scalable from experimentation to full deployment.
"The latest chapter in our ongoing strategic partnership with Core42 now delivers the world’s most capable open-weight models directly into the hands of enterprises, researchers, and governments in the Middle East and around the globe for real-time, reasoning-capable applications," said Andrew Feldman, CEO and co-founder of Cerebras. "Core42’s AI Cloud and Compass API make it seamless to tap into our inference performance, enabling a new generation of agentic workloads at the fastest speeds."
OpenAI’s gpt-oss-120B brings unprecedented reasoning power, long-context understanding (128K tokens), and advanced real-time capabilities to the open-weight ecosystem. From semantic search and code execution to automation and decision intelligence, these models unlock next-generation enterprise AI use cases and deliver real-time reasoning at scale.
Cerebras’ wafer-scale engine (WSE) technology, powering the CS-3 system, and memory-optimized architecture delivers deterministic, ultra-low-latency performance at a radically lower cost-per-token than traditional GPU-based systems. The result: real-time inference for the largest AI models in the world, with the flexibility to scale instantly for both experimental workloads and production deployments.
For enterprises, the Core42 AI Cloud provides direct access to OpenAI’s most advanced open-weight model via a single API. Organizations can now build powerful agentic applications with scalability and efficiency required for mission-critical workloads.
"By running OpenAI gpt-oss on Cerebras hardware within Core42’s AI Cloud and Compass API, we are setting a new benchmark for performance, flexibility, and compliance in AI,” said Kiril Evtimov, CEO of Core42 and Group CTO, G42. “This launch enables our customers to deliver new application capabilities by harnessing cutting-edge open-weight models at the fastest speeds globally with Cerebras Inference.”
- Agentic AI at scale – Build powerful, reasoning-capable AI systems optimized for performance and cost.
- Enterprise-scale performance – Run the fastest, most demanding workloads globally, enabling advanced automation and real-time experiences.
- Industry-leading speed – Integrate gpt-oss-120B into workloads such as reasoning, knowledge retrieval, and long-context generation with ease and efficiency.
The price-performance leader.
Cerebras purpose-built AI infrastructure has the lowest cost per token for OpenAI’s new models while setting the high benchmark for both speed and accuracy. Cerebras and Core42 are offering OpenAI’s latest open models at the following pricing:
- Throughput: 3000 tokens per second
- Input: $0.25 per million tokens
- Output: $0.69 per million tokens
By combining Cerebras’ unmatched inference throughput with Core42’s AI Cloud, enterprises and developers can now access global models with instant scale, for real-time, reasoning-driven applications with industry-leading price-performance.
Available now on Core42 AI Cloud: https://aicloud.core42.ai